What Is a Web Scraping API (and Why You Shouldn`t Build One From Scratch)
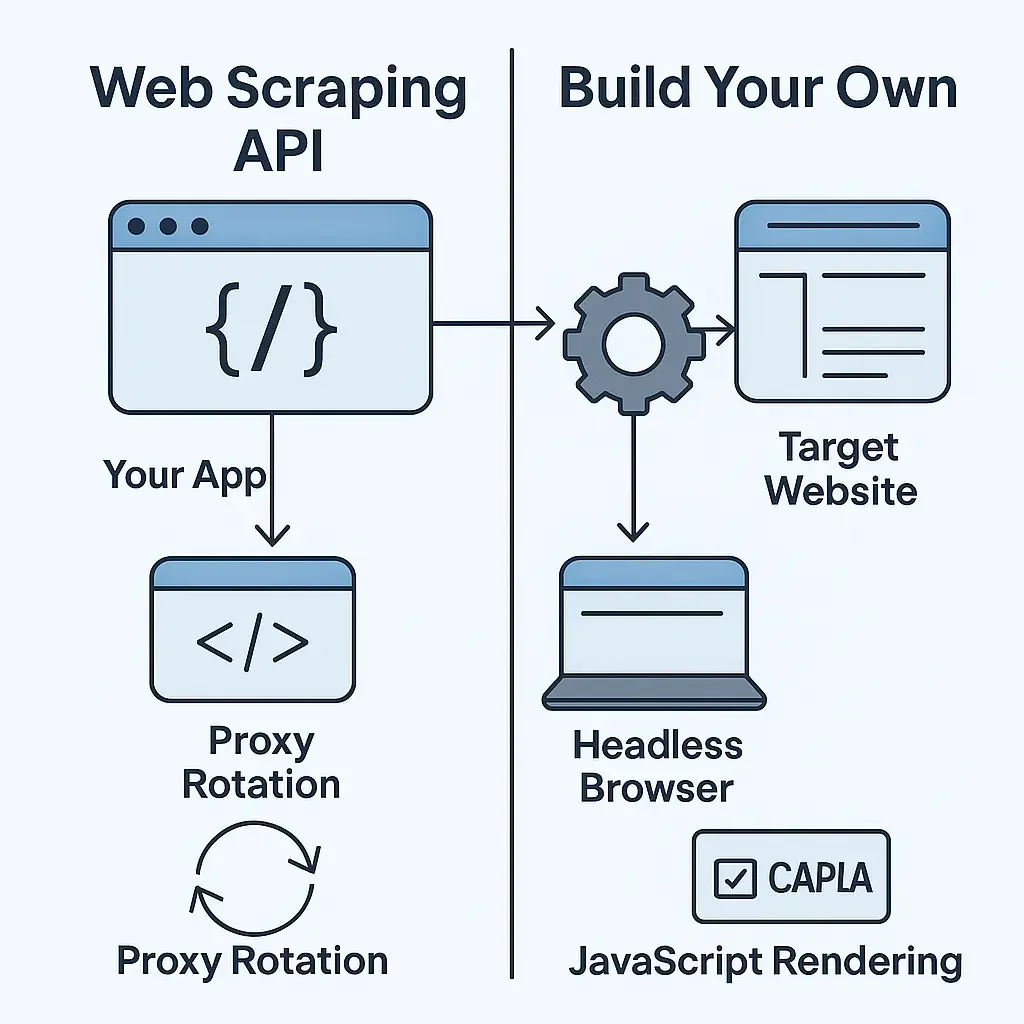
1. Introduction
Web scraping has evolved from a simple side project into one of the most critical tools in modern data-driven applications. Whether you’re tracking product prices, collecting real estate listings, monitoring competitors, or feeding data into AI models, access to structured, real-time information from the web is indispensable.
Yet, despite its importance, web scraping is often misunderstood. Many developers begin with the intention of writing “a small script” to grab some data—only to realize that they’ve stumbled into a complex world of dynamic content, anti-bot systems, rotating IPs, and legal gray zones.
In the early days, a quick Python script using requests and BeautifulSoup was enough to pull down most pages. The internet, however, has changed. Modern sites rely heavily on JavaScript, API calls, and client-side rendering. They actively detect and throttle automated requests. What was once a weekend project can now demand a full team, proxy infrastructure, and continuous maintenance.
This growing complexity gave rise to Web Scraping APIs—services designed to handle the heavy lifting so that developers can focus purely on logic and data. Rather than juggling proxies, browsers, and CAPTCHAs, you send one HTTP request and receive clean, rendered data in response.
This article dives into the technical reality of web scraping today: how it works, why it’s become so challenging to maintain your own scrapers, and what role modern APIs play in abstracting away those obstacles. The goal is to equip developers, data scientists, and engineers with a full understanding of scraping architectures—from do-it-yourself setups to managed API-based solutions.
2. Understanding Web Scraping
At its core, web scraping is a process of automated data retrieval from websites. The scraper sends an HTTP request, downloads the HTML (or rendered DOM), and then extracts the relevant pieces of information—text, links, images, or structured data like product listings or job postings.
Although it sounds straightforward, the underlying mechanics can be sophisticated. A modern scraper is effectively simulating a browser: sending headers, storing cookies, waiting for asynchronous JavaScript calls, and occasionally even mimicking mouse movement or user behavior.
Let’s break down the main components and concepts that define scraping today.
2.1 The Data Flow
The typical scraping pipeline follows this flow:
- Request – Send an HTTP GET or POST request to the target URL.
- Response – Receive HTML or JSON data from the web server.
- Render – If the page relies on JavaScript, use a headless browser to render it fully.
- Parse – Extract the specific elements (titles, prices, tables) using a parser.
- Store – Save the structured data into a database, CSV, or API endpoint.
Here’s a minimal Python example of steps 1–4 using common tools:
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
for book in soup.select("article.product_pod"):
title = book.h3.a["title"]
price = book.select_one(".price_color").text
print(f"{title} — {price}")
This works perfectly for static pages like BooksToScrape. But on a modern website powered by React or Vue, this approach will often return empty content because the data is loaded via AJAX after the page’s initial HTML.
2.2 Static vs. Dynamic Pages
| Page Type | Description | Example Sites | Scraping Approach |
|---|---|---|---|
| Static | HTML is fully loaded on initial request | Blog pages, basic CMS sites | Requests + BeautifulSoup |
| Dynamic | Content loads via JavaScript after page load | Amazon, LinkedIn, Zillow | Playwright, Puppeteer, or Scraping APIs |
For static pages, a simple HTTP client is enough. For dynamic sites, you must use a headless browser that executes JavaScript and waits for the DOM to complete.
Here’s an example using Playwright (Python) for a dynamic site:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://quotes.toscrape.com/js/")
quotes = page.locator(".quote").all_text_contents()
for q in quotes:
print(q)
browser.close()
This short script renders the JavaScript-driven quotes before extracting them. The trade-off: it’s heavier, slower, and harder to scale.
2.3 The Role of Headers, Cookies, and Fingerprints
Web servers rarely treat all requests equally. They evaluate:
- User-Agent headers (browser identity)
- Referrers
- Cookies
- Accept-Language
- TLS fingerprints
If your scraper looks too different from a real browser, it risks being flagged as a bot. Therefore, sophisticated scrapers rotate not only IPs but also browser fingerprints, headers, and session states.
Example: setting headers manually in Python.
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)",
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://google.com",
}
response = requests.get("https://example.com", headers=headers)
A consistent and human-like request profile significantly improves success rates.
2.4 Legal and Ethical Considerations
Scraping is legal in many contexts when accessing publicly available data. However, it becomes problematic when:
- Circumventing authentication or paywalls.
- Violating a site’s Terms of Service.
- Collecting personally identifiable information (PII).
- Causing harm to a site’s infrastructure through excessive requests.
Best practice involves:
- Respecting
robots.txtdirectives. - Using rate limits to avoid burdening servers.
- Identifying yourself through
User-Agentstrings. - Complying with data privacy laws (like GDPR or CCPA).
Scraping responsibly ensures your operations remain sustainable and ethical.
2.5 Rendering Pipelines
When scraping dynamic sites, you often need to render pages to extract data loaded by JavaScript. This can involve multiple layers:
- HTTP Client → fetch HTML shell.
- Headless Browser (Chromium, Firefox) → execute JS, load APIs.
- DOM Parser → extract structured data.
Conceptually:
Request → Render JS → Parse DOM → Extract Data → Store
Each stage introduces cost, latency, and potential points of failure. Managing these efficiently is why dedicated scraping frameworks and APIs exist.
2.6 Parsing Techniques
Once the content is retrieved, parsing converts it into usable data. Common methods:
- CSS Selectors (e.g.,
.product-title) - XPath (e.g.,
//h2/text()) - Regex (only for fallback, brittle)
- JSON parsing (when sites load data via inline API calls)
For instance, using lxml with XPath:
from lxml import html
import requests
page = requests.get("https://books.toscrape.com/")
tree = html.fromstring(page.content)
titles = tree.xpath('//h3/a/@title')
prices = tree.xpath('//p[@class="price_color"]/text()')
for title, price in zip(titles, prices):
print(title, price)
This approach is fast and robust for predictable structures, but becomes fragile when sites frequently change their layout.
2.7 Why Scraping Is Getting Harder
Websites are adopting sophisticated anti-bot technologies such as:
- Cloudflare bot management
- CAPTCHAs
- Fingerprint-based detection
- Behavioral analytics
- Dynamic content APIs
Each of these forces developers to continuously update and maintain their scrapers, driving up cost and complexity.
The solution that emerged is scraping-as-a-service — specialized APIs that manage these moving parts automatically.
3. The Traditional Approach: Building Your Own Scraper
Before cloud-based scraping APIs became popular, developers built everything manually. A scraper might start as a few lines of code, but scaling it into a production-ready system quickly turns into a major engineering effort.
The traditional scraper typically includes:
- An HTTP client to fetch pages.
- A parser (HTML, JSON, or regex).
- A scheduler or queue system.
- Proxy rotation and retry logic.
- Storage (databases, CSVs, message queues).
Let’s explore how these elements look in real-world code.
3.1 Basic Scraper in Python
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
headers = {"User-Agent": "Mozilla/5.0"}
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
for product in soup.select(".product_pod"):
title = product.h3.a["title"]
price = product.select_one(".price_color").text
print(f"{title} -> {price}")
This script is quick, clean, and effective — for static pages.
But once you scale to thousands of URLs, you’ll need retries, concurrency, and IP management.
3.2 Building the Same Scraper in Go
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
res, err := http.Get("https://books.toscrape.com/")
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
log.Fatal(err)
}
doc.Find(".product_pod").Each(func(i int, s *goquery.Selection) {
title := s.Find("h3 a").AttrOr("title", "")
price := s.Find(".price_color").Text()
fmt.Printf("%s — %s\n", title, price)
})
}
Go is excellent for concurrency, but when sites use JavaScript to render content, even Go’s speed won’t help — you’ll fetch empty shells.
3.3 Scraper in JavaScript (Node.js + Puppeteer)
import puppeteer from "puppeteer";
const scrape = async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto("https://quotes.toscrape.com/js/", { waitUntil: "networkidle2" });
const quotes = await page.$$eval(".quote span.text", spans =>
spans.map(s => s.textContent)
);
quotes.forEach(q => console.log(q));
await browser.close();
};
scrape();
With Puppeteer, you can handle JavaScript-heavy sites. However:
- It’s CPU-heavy.
- Requires proxy management to avoid bans.
- Adds deployment complexity for thousands of concurrent browsers.
3.4 Basic Bash Scraping Example
curl -A "Mozilla/5.0" https://example.com | grep "title"
This is useful for quick tests or static HTML—but not sustainable for serious scraping.
When you reach production scale, these ad-hoc scripts become brittle and hard to maintain.
3.5 Key Takeaways
- DIY scrapers give you control, but you pay with time and maintenance.
- You’ll face issues with scaling, IP blocking, and browser rendering.
- Each programming language offers tools, but none solve the infrastructure challenge natively.
That brings us to the next section—understanding the hidden challenges that make in-house scraping so expensive.
4. The Hidden Challenges of DIY Scraping
The initial setup for a scraper might take hours. The maintenance can take months.
Below are the major pain points developers encounter when they try to scale their scraping pipelines.
4.1 Proxy Management and IP Bans
Websites monitor traffic patterns. If they see too many requests from the same IP, you get blocked.
Symptoms of IP blocking:
- HTTP 403 or 429 errors
- CAPTCHAs
- Empty responses or redirects
To avoid this, you must rotate proxies — often from residential IP pools.
Example proxy rotation in Python:
import random, requests
proxies = [
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
]
url = "https://httpbin.org/ip"
proxy = {"http": random.choice(proxies), "https": random.choice(proxies)}
resp = requests.get(url, proxies=proxy)
print(resp.json())
Managing this across thousands of requests becomes a full system by itself.
4.2 Handling JavaScript-Heavy Pages
Modern websites load data dynamically through API calls or frameworks like React and Vue.
A raw HTTP request won’t include any of that content.
Example (Go + chromedp for JS rendering):
package main
import (
"context"
"fmt"
"time"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var html string
chromedp.Run(ctx,
chromedp.Navigate("https://quotes.toscrape.com/js/"),
chromedp.Sleep(2*time.Second),
chromedp.OuterHTML("html", &html),
)
fmt.Println(html[:500])
}
This works well for a handful of URLs but is too slow for production-scale scraping.
4.3 Captchas and Anti-Bot Systems
Sites like Google, Amazon, and LinkedIn employ sophisticated anti-bot systems.
Common triggers include:
- Unusual request frequency.
- Identical user-agents.
- Lack of JavaScript or mouse movement.
You can reduce detection by adding random delays and rotating headers.
Example (Bash random delay):
for i in {1..10}; do
curl -s -A "Mozilla/5.0" "https://example.com/page/$i" > "page_$i.html"
sleep $((RANDOM % 5 + 2))
done
Small randomization like this helps, but it doesn’t eliminate detection at scale.
4.4 Concurrency and Scaling
Even if your scraper works perfectly on one machine, scaling it to thousands of pages means building:
- Distributed queues (Redis, RabbitMQ).
- Worker pools.
- Rate limiters.
- Retry logic and backoff algorithms.
Example concurrency with Go goroutines:
package main
import (
"fmt"
"net/http"
"sync"
)
func fetch(url string, wg *sync.WaitGroup) {
defer wg.Done()
resp, err := http.Get(url)
if err == nil {
fmt.Println(url, resp.Status)
}
}
func main() {
var wg sync.WaitGroup
urls := []string{"https://example.com", "https://golang.org", "https://books.toscrape.com"}
for _, u := range urls {
wg.Add(1)
go fetch(u, &wg)
}
wg.Wait()
}
This concurrency pattern is powerful but adds complexity for retries, rate limits, and error handling.
4.5 Maintenance and Code Fragility
Websites change DOM structures regularly.
A simple class name change (.price → .new-price) can break your parser and return null values.
That means ongoing:
- DOM inspection
- XPath/CSS updates
- Regression testing
Each small change ripples through your pipeline.
4.6 Cost of “Free” Scraping
While open-source libraries are free, maintaining scrapers isn’t:
- Proxy subscriptions
- Browser containers (Docker)
- Compute costs for headless rendering
- DevOps for monitoring uptime
In most organizations, these costs exceed the price of managed scraping APIs within months.
4.7 Summary
| Challenge | Impact | Mitigation |
|---|---|---|
| IP bans | Requests blocked | Proxy rotation, throttling |
| JavaScript rendering | Missing content | Headless browsers |
| Captchas | Requests halted | Behavior simulation, solver services |
| Scaling | Infrastructure sprawl | Queues, rate-limiting |
| Maintenance | Frequent breakage | Continuous DOM updates |
These are the hidden expenses that turn a “quick scraper” into a full-scale engineering problem.
The next sections will explain how Web Scraping APIs abstract these complexities, letting teams focus solely on data, not infrastructure.
5. The Rise of Scraping APIs
After years of building and maintaining fragile in-house scrapers, developers began asking a simple question:
“Why am I managing proxies, browsers, and CAPTCHAs when all I want is data?”
The answer was Web Scraping APIs—services that handle all of the low-level scraping challenges through a single HTTP endpoint.
Instead of launching headless browsers or maintaining proxy pools, you can send one request like this:
import requests
API_KEY = "YOUR_API_KEY"
url = "https://quotes.toscrape.com/js/"
params = {
"url": url,
"render_js": True,
"geo": "us",
"api_key": API_KEY
}
r = requests.get("https://api.scrapingforge.com/v1", params=params)
print(r.status_code)
print(r.text[:400])
The API orchestrates:
- Proxy rotation
- Browser rendering
- Retries and anti-bot bypass
- Clean output formatting
The result? Developers focus on data pipelines, not network plumbing.
5.1 How Scraping APIs Work
A typical scraping API flow looks like this:
Client Request → API Endpoint → Proxy Layer → Headless Browser → Target Site → Parsed Output
- Proxy Layer: Routes requests through a global IP pool.
- Browser Engine: Executes JavaScript (e.g., Chromium, Playwright).
- Parser / Normalizer: Extracts structured data or returns rendered HTML.
- Response: Sent back to the client as JSON or HTML.
Here’s the same process with Go:
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
apiKey := "YOUR_API_KEY"
url := fmt.Sprintf("https://api.scrapingforge.com/v1?url=https://example.com&render_js=true&api_key=%s", apiKey)
resp, _ := http.Get(url)
body, _ := ioutil.ReadAll(resp.Body)
fmt.Println(string(body[:500]))
}
One request replaces hundreds of lines of infrastructure code.
5.2 Typical Use Cases
| Use Case | Description |
|---|---|
| E-commerce | Track competitor pricing, product availability |
| SEO / SERP | Collect search results across locations |
| Real Estate | Aggregate listings from multiple sources |
| AI / ML | Gather training datasets from diverse sources |
| Market Intelligence | Monitor brand mentions, reviews, or trends |
The rise of Web Scraping APIs parallels the evolution of cloud computing:
just as AWS abstracted physical servers, scraping APIs abstract data collection.
6. Core Features of a Modern Scraping API
A mature scraping API is more than just an HTML downloader. It’s an orchestration system designed to handle network, rendering, and compliance complexity at scale.
Let’s examine its key components.
6.1 Rotating Proxy Pools
Instead of relying on a single IP, modern APIs automatically rotate requests through thousands of residential and datacenter proxies.
Example: API call with region targeting
curl "https://api.scrapingforge.com/v1?url=https://example.com&geo=de&api_key=YOUR_API_KEY"
geo=de→ routes through German IPs.- Each request uses a unique proxy.
- Ensures minimal blocking and accurate localized results.
6.2 Headless Browser Rendering
Websites that rely on client-side JavaScript (React, Vue, Angular) require execution before data can be extracted.
Example using Node.js to request rendered HTML:
import fetch from "node-fetch";
const API_KEY = "YOUR_API_KEY";
const target = "https://quotes.toscrape.com/js/";
const response = await fetch(
`https://api.scrapingforge.com/v1?url=${encodeURIComponent(target)}&render_js=true&api_key=${API_KEY}`
);
const html = await response.text();
console.log(html.slice(0, 400));
Behind the scenes, the API launches a headless browser, waits for the DOM to load, and sends you the final rendered page.
6.3 Automatic Retries and Error Recovery
Scraping APIs include built-in retry logic. If a request times out or encounters a 403, the system retries with a new IP.
Example JSON response with retry metadata:
{
"url": "https://example.com",
"status": 200,
"retries": 2,
"proxy_used": "fr-residential-203.0.113.56",
"duration_ms": 4321
}
This level of visibility helps engineers monitor performance and reliability without custom retry loops.
6.4 Structured Data Extraction
Some APIs allow direct extraction of metadata, links, or JSON payloads.
Example (Python):
params = {
"url": "https://example.com/product/123",
"extract": "meta,links,prices",
"api_key": "YOUR_API_KEY"
}
data = requests.get("https://api.scrapingforge.com/v1", params=params).json()
print(data["meta"]["title"])
print(data["prices"])
This feature removes the need for parsing libraries and XPath logic in client applications.
6.5 Session Persistence
When scraping multi-step flows (pagination, login sessions), session persistence ensures continuity.
Example (Go):
params := "?url=https://example.com/page1&session=my-session&api_key=YOUR_API_KEY"
resp, _ := http.Get("https://api.scrapingforge.com/v1" + params)
Subsequent requests with the same session parameter reuse cookies and browser context.
6.6 Geo-Targeting
For businesses tracking localized search results or pricing differences:
curl "https://api.scrapingforge.com/v1?url=https://example.com&geo=us&render_js=true&api_key=YOUR_API_KEY"
You can test how pages appear in specific regions—essential for SEO, e-commerce, and ad intelligence.
6.7 Smart Throttling and Compliance
High-quality APIs throttle requests automatically to respect site limits.
They monitor for rate-limiting signals and adjust concurrency dynamically.
This approach reduces risk and promotes responsible scraping.
7. When It Still Makes Sense to Build Your Own
While scraping APIs simplify most workflows, there are valid cases where rolling your own system is beneficial.
7.1 Controlled Internal Environments
If you’re scraping your own company’s websites, internal tools, or intranet systems, you might not need external proxies or rendering engines.
Example:
- Internal dashboards
- Legacy business systems
- Closed network reporting
In such cases, a local scraper in Python or Go is sufficient.
7.2 Specialized Research or Academic Projects
For research tasks requiring experimental crawlers (e.g., studying web graph behavior), you may want full control over requests, timing, and analysis.
Example minimal crawler in Python:
import requests, re
from urllib.parse import urljoin
def crawl(base_url, depth=1):
if depth == 0:
return
print("Crawling:", base_url)
html = requests.get(base_url).text
for link in re.findall(r'href="(.*?)"', html):
if link.startswith("http"):
crawl(link, depth-1)
crawl("https://example.com", 2)
Such scrapers are ideal for academic exploration, not production-scale data collection.
7.3 High-Volume Enterprises
At massive scale (millions of requests per day), companies sometimes invest in internal scraping clusters to reduce per-request API costs.
They build:
- Dedicated proxy networks
- Browser farms (Playwright / Puppeteer)
- Monitoring dashboards
However, this only makes sense when data volume justifies the operational overhead.
7.4 Compliance or Privacy Constraints
Some industries require keeping all traffic within their infrastructure for compliance.
In that case, custom internal scrapers ensure data never leaves their controlled environments.
7.5 Summary
| Scenario | Recommended Approach |
|---|---|
| Small to mid-size startups | Use managed scraping API |
| Enterprise-scale data harvesting | Hybrid (internal + API) |
| Research / academic | Build lightweight in-house |
| Internal dashboards | Local scraper only |
| Legal or privacy-restricted industries | On-premise solution |
Even with these exceptions, 80–90% of real-world scraping use cases benefit from API abstraction — simplicity, scalability, and reliability out of the box.
8. Cost & Engineering Trade-offs
Every developer faces the same decision:
Should I build my own scraper or pay for a scraping API?
At first glance, self-hosting seems cheaper — you control everything.
But once you factor in proxy networks, scaling, and maintenance, the economics shift rapidly.
8.1 The True Cost of a DIY Scraper
Let’s estimate the ongoing monthly expenses for a small team scraping ~1 million pages/month.
| Component | Typical Cost (Monthly) | Notes |
|---|---|---|
| Proxy network (residential + datacenter mix) | $200–$600 | IP rotation essential to avoid bans |
| Headless browser infrastructure (servers/containers) | $150–$400 | CPU-intensive, requires scaling |
| CAPTCHA solving services | $50–$150 | Required for high-security sites |
| Monitoring & retries | $50–$100 | Logs, alerting, error handling |
| DevOps maintenance | ~20–30 hrs developer time | Ongoing script updates and scaling fixes |
Approximate total: $500 – $1,200/month + engineering time.
Even at the low end, that’s easily >$6,000/year, not counting developer salaries.
8.2 Time Is the Hidden Cost
Developers spend significant time debugging scraper issues:
- Changing selectors when DOMs update
- Managing blocked IPs
- Handling intermittent 403/429 errors
- Scaling infrastructure
A simple math example:
# 5 hours/week maintaining scraper
# 5 hours × 4 weeks × $50/hour = $1,000/month in developer time
That’s the hidden tax of in-house scraping.
8.3 When APIs Win Economically
Scraping APIs like ScrapingForge, ScraperAPI, or Oxylabs pool infrastructure across thousands of customers.
This gives you economies of scale:
| Metric | DIY Scraper | Scraping API |
|---|---|---|
| Setup time | Days–weeks | Minutes |
| Scaling | Manual servers | Automatic |
| Proxy rotation | Self-managed | Built-in |
| Browser rendering | Needs config | Built-in |
| Maintenance | High | Minimal |
| Monthly cost | $500–$1200 | $49–$199 typical starter tier |
For most small to mid-size teams, APIs win by both cost and focus — allowing developers to build products, not infrastructure.
8.4 Hybrid Approaches
Larger organizations often adopt hybrid systems:
- Use Scraping APIs for general data collection.
- Run internal scrapers for high-volume or proprietary tasks.
Example architecture:
Internal Crawler → Scraping API for hard targets → Central Data Pipeline → Storage (S3/DB)
This combines reliability with flexibility.
8.5 Performance Considerations
While APIs are convenient, latency can be higher due to proxy hops and browser rendering.
A quick latency benchmark (hypothetical):
| Task | DIY Scraper | Scraping API |
|---|---|---|
| Static HTML | ~1s | ~1.5s |
| JS-heavy page | 3–6s | 4–7s (browser render) |
| Geo-targeted | 2–4s | 3–5s |
The performance gap is small, but APIs provide higher success rates (95–99%) compared to DIY setups (~60–80%).
8.6 Summary
| Factor | DIY Scraper | Scraping API |
|---|---|---|
| Cost | Moderate hardware, high maintenance | Subscription model |
| Scalability | Manual scaling | Elastic scaling |
| Reliability | Varies | Consistent |
| Time to market | Weeks | Hours |
| Maintenance | Continuous | Minimal |
For most startups and research teams, the total cost of ownership makes APIs the logical choice.
9. Best Practices for Large-Scale Scraping
Even with the best tools, scraping at scale demands careful engineering.
The goal isn’t just to gather data — it’s to do it responsibly, efficiently, and sustainably.
9.1 Respectful Scraping
Web scraping should always follow ethical and technical courtesy:
- Respect robots.txt guidelines.
- Add delays between requests.
- Avoid flooding target servers.
- Identify your crawler with a meaningful User-Agent.
Example (Python delay):
import time, requests
for i in range(1, 6):
r = requests.get(f"https://example.com/page/{i}")
print(r.status_code)
time.sleep(2) # 2-second delay between requests
This prevents IP bans and ensures responsible use.
9.2 Randomized Fingerprinting
Avoid detection by rotating headers, devices, and user-agents.
Example (JavaScript):
import fetch from "node-fetch";
const agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)",
"Mozilla/5.0 (X11; Linux x86_64)"
];
const url = "https://example.com";
for (let i = 0; i < 3; i++) {
const res = await fetch(url, { headers: { "User-Agent": agents[i] } });
console.log("Request", i + 1, "Status:", res.status);
}
Small randomization steps significantly improve scraping success rates.
9.3 Rate Limiting and Queues
For thousands of pages, you’ll need concurrency limits to prevent overload.
Example using Go concurrency control:
package main
import (
"fmt"
"net/http"
"time"
)
func worker(id int, jobs <-chan string) {
for url := range jobs {
resp, _ := http.Get(url)
fmt.Println("Worker", id, "→", url, resp.Status)
time.Sleep(1 * time.Second)
}
}
func main() {
jobs := make(chan string, 5)
for i := 1; i <= 3; i++ {
go worker(i, jobs)
}
for _, u := range []string{"https://a.com", "https://b.com", "https://c.com"} {
jobs <- u
}
close(jobs)
time.Sleep(5 * time.Second)
}
This prevents “bursty” traffic that can trigger site defenses.
9.4 Data Storage and Normalization
Scraping is only half the process. You also need structured, queryable storage.
Example:
- Save JSON responses in S3 or a database.
- Standardize fields (e.g.,
title,price,url) across sources. - Use pipelines like Airflow, Prefect, or custom ETL scripts.
Simple Bash pipeline:
curl "https://api.scrapingforge.com/v1?url=https://example.com&api_key=KEY" | jq '{title: .meta.title, price: .prices}' >> data.json
9.5 Monitoring and Logging
Always log:
- HTTP status codes
- Request duration
- Proxy/country used
- Error types
This helps you identify patterns (e.g., repeated 403s or slow targets).
Example log format:
{
"timestamp": "2025-10-15T10:00:00Z",
"url": "https://example.com",
"status": 200,
"proxy": "us-residential",
"duration_ms": 3450
}
Centralized logging (e.g., ELK Stack or Grafana) provides visibility into scraper health.
9.6 Retry and Backoff Strategies
Implement exponential backoff for failed requests to avoid aggressive retries.
Example (Python):
import time, requests
def fetch(url):
for i in range(3):
r = requests.get(url)
if r.status_code == 200:
return r.text
sleep = 2 ** i
print(f"Retrying in {sleep}s...")
time.sleep(sleep)
return None
This balances speed and politeness toward target sites.
9.7 Legal and Compliance Awareness
Stay aligned with:
- Data privacy laws (GDPR, CCPA).
- Public data usage only.
- Clear documentation of sources and purpose.
Following these ensures long-term sustainability of scraping operations.
9.8 Summary
| Practice | Purpose |
|---|---|
| Respect rate limits | Avoid IP bans |
| Randomize headers | Prevent bot detection |
| Use structured storage | Easier data integration |
| Implement retries | Increase success rate |
| Monitor performance | Detect slowdowns or failures |
| Follow legal norms | Ensure compliance |
Building responsible scraping pipelines increases both reliability and reputation.
10. The Future of Web Scraping APIs
The web is evolving fast — and so is the way we extract and use its data.
As sites become more dynamic, APIs must adapt to increasingly complex detection systems, rendering models, and compliance regulations.
Let’s explore what’s next for web scraping technologies.
10.1 Browserless and Serverless Architectures
Traditional headless browsers like Chrome or Playwright require dedicated compute resources.
The next generation of APIs is going serverless—executing rendering workloads only when needed and scaling instantly.
This allows:
- Faster cold starts for small jobs.
- Lower cost per request due to efficient resource allocation.
- Automatic horizontal scaling without managing containers.
Example concept flow:
Request → Lambda/Serverless Render → Parse → Return JSON
These architectures eliminate the need for always-on browser clusters.
10.2 AI-Enhanced Scraping
Large Language Models (LLMs) are transforming data extraction.
Instead of defining rigid selectors, developers can simply describe what they need.
Example (pseudo-API call):
{
"url": "https://example.com/product",
"query": "extract product title, price, and availability"
}
The API interprets this instruction using natural language, extracting structured results automatically.
Future scraping APIs will blend AI parsing, pattern recognition, and adaptive learning to handle unpredictable DOM changes.
10.3 Ethical and Legal Automation
Scraping responsibly will soon be enforced automatically.
Next-gen APIs already include features like:
- robots.txt compliance
- opt-out detection
- data type classification (e.g., personal vs. public)
This ensures developers stay compliant with GDPR, CCPA, and regional data laws without manual oversight.
10.4 Integration with Data Pipelines
Scraping APIs are merging directly into analytics and AI ecosystems.
Expect native connectors for:
- Snowflake, BigQuery, S3
- Airflow and Dagster pipelines
- Vector databases for semantic search
This means you can move from “data extraction” to “data insight” seamlessly — no custom ETL code required.
10.5 The Rise of Real-Time Scraping
Static datasets are becoming outdated quickly.
Real-time scraping APIs allow developers to:
- Subscribe to live change feeds from websites.
- Detect content updates instantly.
- Trigger downstream workflows (like alerting or ML retraining).
This is especially powerful for:
- Pricing intelligence
- Stock monitoring
- News aggregation
10.6 Summary
| Trend | Impact |
|---|---|
| Serverless scraping | Scalable, cost-efficient data collection |
| AI-driven parsing | Human-like content extraction |
| Built-in compliance | Automatic data ethics enforcement |
| Real-time APIs | Continuous data freshness |
| Pipeline integration | Seamless ingestion into analytics systems |
Web scraping APIs are evolving from simple data fetchers into intelligent, compliant data orchestration layers.
11. Conclusion
Modern data teams no longer need to fight CAPTCHAs, rotate proxies, or maintain fragile browser clusters.
The shift from manual scrapers to scraping APIs mirrors how cloud computing replaced physical servers — a natural evolution driven by simplicity and scale.
If you’re still maintaining your own infrastructure, ask yourself:
Is my team focused on data insights or debugging request headers?
By offloading the infrastructure layer to a managed scraping API, you gain:
- Faster development cycles
- Higher data reliability
- Lower operational cost
- Global scalability with compliance
The future of web scraping is abstraction, and developers who embrace it will move faster, spend less, and build smarter.
🚀 Try ScrapingForge for Free
If you want to see what modern scraping feels like in action, start your first scrape in seconds:
👉 Try for free at dash.scrapingforge.com
Send your first request, render JavaScript, rotate proxies, and get structured JSON — all from a single API call.