Ecommerce Web Scraping & Price Scraping Guide
Web scraping ecommerce prices
In this blog post, I’ll explain what price scraping is and show you how to build a price scraper using Zara’s website as an example. You’ll learn how to extract prices from ecommerce sites using Python. Scraping ecommerce data isn’t as easy as it looks. The programming logic itself isn’t very hard, but the main challenge lies in handling the barriers that ecommerce websites put in place. You’ll need to manage proxies, JavaScript rendering, and CAPTCHAs that can block your scraping requests. In this guide, I’ll show you how to scrape prices from websites using Python, Scrapy, and BeautifulSoup.
Scraping product prices with Python code
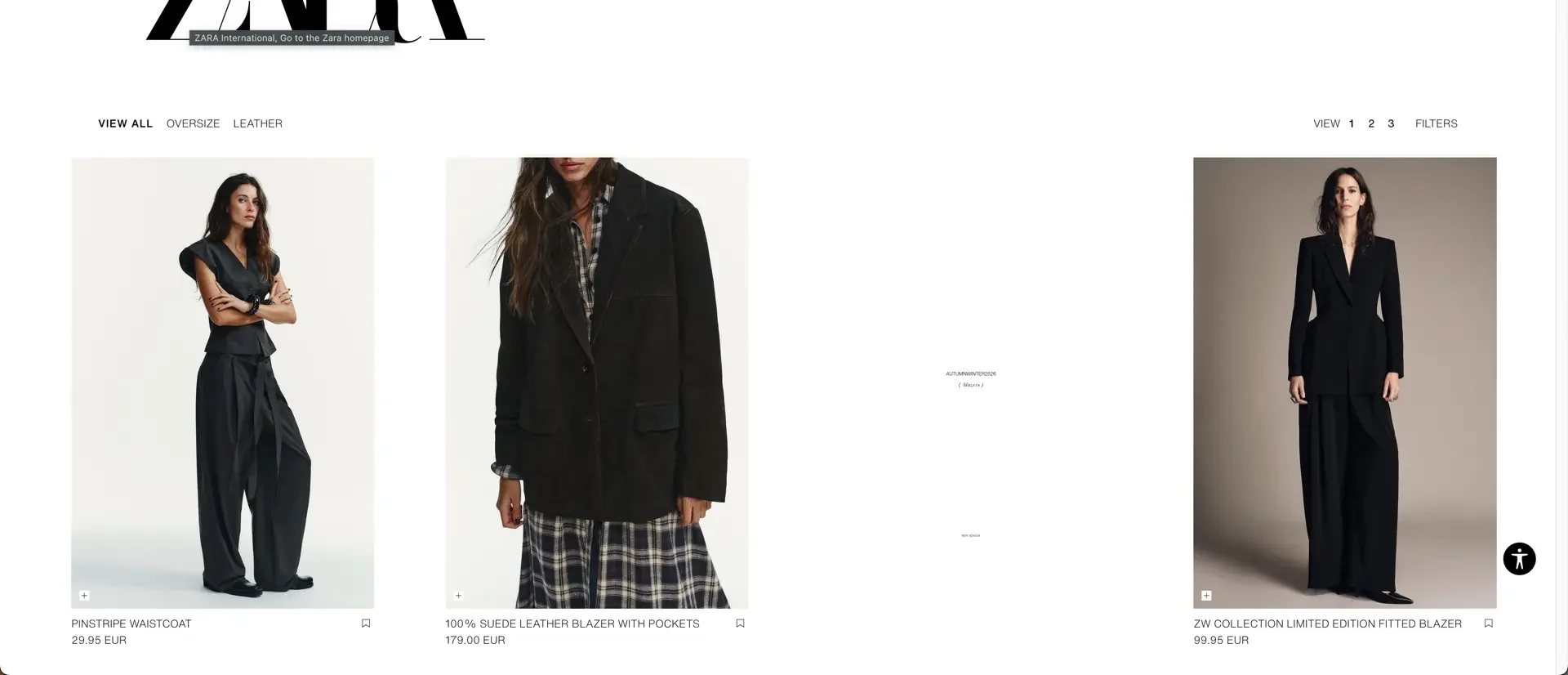
Let’s scrape Zara’s women’s blazers collection.
First, make sure you have the required libraries installed — Python 3+, Scrapy, and BeautifulSoup.
Scrapy is a powerful Python framework for web crawling and data extraction.
It provides tools for navigating websites and saving structured data in accessible formats.
Scrapy uses spiders — Python classes that define how to browse web pages and extract the information you need.
BeautifulSoup is another Python library designed to parse and navigate HTML efficiently, making it simple to find and extract specific elements from web pages.
Run this command to install the libraries
pip3.8 install scrapy beautifulsoup4
Create a new folder:
mkdir zara
Then set up a new project:
scrapy startproject zara_price
This command will create a new Scrapy project for you. Once it’s done, let’s explore how the data is structured on the website.
Ecommerce website data structure
Before writing your Scrapy spider, analyze the structure of the website. Start by opening the Women’s Blazers section on Zara’s website in your browser. Right-click anywhere on the page and select Inspect to open the Developer Tools. This allows you to view the page’s HTML source code and find the elements that contain product names and prices.
For Zara, product details are typically located within a <div> tag with the class product-grid-product-info.
The product name is usually found inside an <h2> tag, while the price appears within a <span> tag with the class money-amount__main.
Understanding this structure is crucial before you start coding.
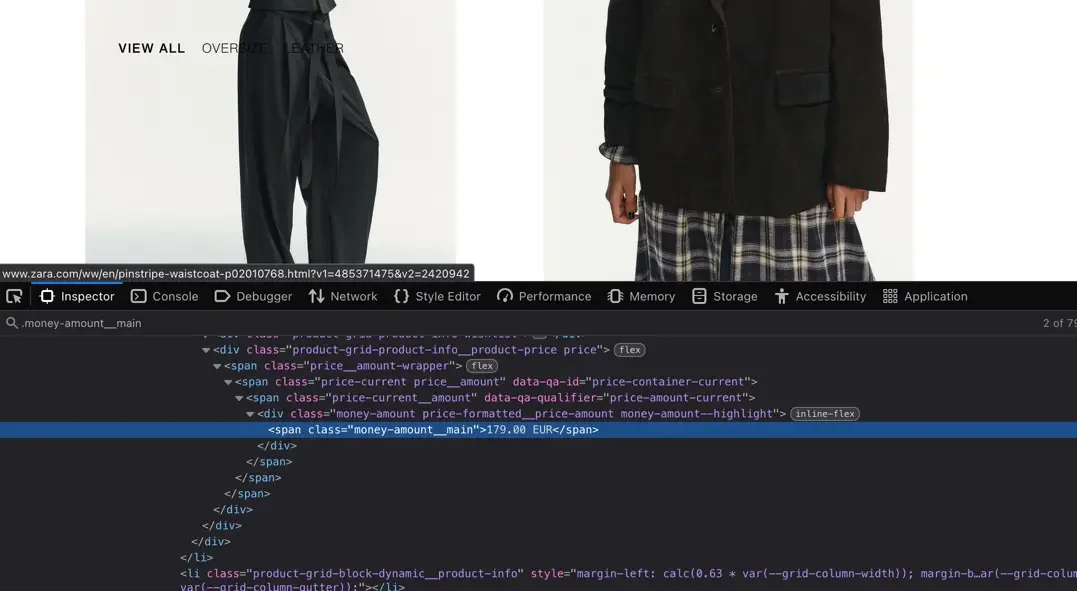
Note: Websites sometimes change their HTML structure, so this information may differ in the future.
Creating the Zara Scrapy Spider
To start building your Zara web scraper, navigate to your project’s spiders directory and create a new file named spider.py.
This file will contain the core logic for scraping product data from Zara’s website.
cd spiders
touch spider.py
Integrating ScrapingForge scraping method
Zara’s website, like many modern ecommerce sites, uses JavaScript rendering and anti-bot measures that can block direct scraping requests. To handle this effectively, we’ll use the ScrapingForge API. Import the libraries and add the ScrapingForge integration code:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scrapingforge_request(target_url: str, config: dict = None):
if config is None:
config = {}
api_key = "SCRAPINGFORGE_API_KEY"
base_url = "https://api.scrapingforge.com/api/v1/scraper"
params = {'url': target_url}
params["render_js"] = "true"
params["premium_proxy"] = "true"
params["format"] = "html"
full_url = f"{base_url}?{urlencode(params)}"
headers = {"Authorization": f"Bearer {api_key}"}
return full_url, headers
The get_scrapingforge_url() function:
- Accepts the target URL as input.
- Appends your ScrapingForge API key and enables the render option for JavaScript-heavy pages.
- Returns a fully formatted ScrapingForge proxy URL, ensuring your requests are routed through ScrapingForge servers.
This approach helps bypass anti-bot detection systems and allows Scrapy to scrape dynamic pages seamlessly.
You can get API key here - https://dash.scrapingforge/app/api-keys - Create a new key or use an existing one, and replace the api_key variable in your code.
Writing the Main Zara Scrapy Spider Class
In Scrapy, each scraper is defined as a Spider class, which specifies how to crawl and extract data from a target website. Now that ScrapingForge is set up, let’s write the main spider that will scrape product data from Zara’s website. Here’s the code for the main spider class:
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
base_urls = [
'https://www.zara.com/ww/en/woman-blazers-l1055.html?v1=2420942&page=1',
'https://www.zara.com/ww/en/woman-blazers-l1055.html?v1=2420942&page=2',
'https://www.zara.com/ww/en/woman-blazers-l1055.html?v1=2420942&page=3',
]
for url in base_urls:
full_url, headers = get_scrapingforge_request(url)
yield scrapy.Request(url=full_url, headers=headers, callback=self.parse)
How It Works
- name =
"zara_products"` — the unique spider identifier used to run it from the terminal. start_requests()— defines starting URLs (the first 3 pages of Zara’s Woman Blazers).- Each URL passes through
get_scrapingforge_url(), ensuring requests are routed via ScrapingForge, which handles JavaScript rendering and IP rotation.
callback=self.parse sends the HTML to the parse() method for processing.
Parsing the HTML Response
Next, define the parse() method — the core of any Scrapy spider.
It processes the downloaded HTML and extracts the product information you need.
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('.product-grid-product-info__name')
price = product.select_one('span.money-amount__main')
yield {
'product_name': product_name.get_text(strip=True) if product_name else None,
'price': price.get_text(strip=True) if price else None,
}
What This Does
Converts the response into a BeautifulSoup object for easy parsing. Finds each product container (div.product-grid-product-info).
Extracts:
- Product name →
<h2>tag. - Price →
<span>withmoney-amount__main. - Uses
get_text(strip=True)to clean up whitespace. - Yields a dictionary that Scrapy later exports or processes.
Running the Spider
We created Scrapy spider, now let's run it.
scrapy crawl zara_products -o zara_womens_prices.csv
This command will extract all data into a CSV file. You’ll now have clean, structured product data ready for analysis or integration.
Full Zara Spider Code with ScrapingForge Integration
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scrapingforge_request(target_url: str, config: dict = None):
"""
Build a ScrapingForge API request URL and headers like the Go version.
"""
if config is None:
config = {}
api_key = "YOUR_API_KEY"
base_url = "https://api.scrapingforge.com/api/v1/scraper"
params = {'url': target_url}
params["render_js"] = "true"
params["premium_proxy"] = "true"
params["format"] = "html"
full_url = f"{base_url}?{urlencode(params)}"
headers = {"Authorization": f"Bearer {api_key}"}
return full_url, headers
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
base_urls = [
'https://www.zara.com/ww/en/woman-blazers-l1055.html?v1=2420942&page=1',
'https://www.zara.com/ww/en/woman-blazers-l1055.html?v1=2420942&page=2',
'https://www.zara.com/ww/en/woman-blazers-l1055.html?v1=2420942&page=3',
]
for url in base_urls:
full_url, headers = get_scrapingforge_request(url)
yield scrapy.Request(url=full_url, headers=headers, callback=self.parse)
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('.product-grid-product-info__name')
price = product.select_one('span.money-amount__main')
yield {
'product_name': product_name.get_text(strip=True) if product_name else None,
'price': price.get_text(strip=True) if price else None,
}
By combining Scrapy, BeautifulSoup, and ScrapingForge, you’ve built a Zara web scraper capable of extracting product names and prices from dynamic, JavaScript-heavy pages. Using ScrapingForge’s API ensures your scraper runs smoothly without IP bans or rendering issues, while Scrapy efficiently structures and exports your data.
This same setup can be adapted for other eCommerce sites, making it a flexible foundation for price monitoring, market research, or product data analysis projects.
🚀 Start optimizing your scraping workflow today with Scrapy + ScrapingForge — a perfect duo for effortless, high-performance web scraping in Python.
HTTP Status Codes in Web Scraping & How to Handle
Complete guide to HTTP status codes in web scraping. Learn how to handle 429, 503, 520 errors with retry logic, proxy rotation, and Python code examples.
How to Bypass CreepJS Browser Fingerprinting
Bypass CreepJS detection using Puppeteer, Playwright, Selenium, chromedp, and Camoufox. Full guide with Xvfb, screenshots, and anti-fingerprinting techniques.