Web scraping with PHP
In this tutorial, I will explore web scraping with PHP and check whether its good or not. While JavaScript and Python dominate the web scraping field, PHP offers unique advantages for certain use cases, especially if you are already working within a PHP ecosystem.
I will cover the fundamentals of HTTP requests, introduce libraries like Guzzle and DomCrawler, and build a real-world scraper to extract data from Hacker News.
What You Will Learn
By the end of this tutorial, you will know how to make HTTP requests using PHP's native cURL and the Guzzle library. You will understand why headers are important and how to configure them to avoid detection. I will show you how to parse HTML using DomCrawler with CSS and XPath selectors, implement asynchronous requests to speed up your scraper, handle errors gracefully, and use ScrapingForge API to bypass anti-bot protection.
Project Setup
Our project will scrape Hacker News to demonstrate core web scraping concepts. The complete source code is available in our GitHub repository. First, let's create a new PHP project using Composer:
mkdir php-scraper
cd php-scraper
composer init
composer require guzzlehttp/guzzle
composer require symfony/dom-crawler
composer require symfony/css-selector
Making HTTP Requests with cURL
PHP's native cURL library is a powerful tool for making HTTP requests. Here is a basic example that fetches the Hacker News homepage. First, we initialize a cURL connection and configure the request URL and method. Then we set options to return the response as a string and enable automatic redirect handling. Finally, we execute the request and close the connection to free up resources.
<?php
$ch = curl_init();
$url = "https://news.ycombinator.com/";
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPGET, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
echo $response;
?>
Understanding HTTP Requests
While I will not dive deep into HTTP protocol details (you can read the MDN HTTP Overview for that), it is important to understand the basics. GET requests retrieve data from a server and are used for most scraping tasks. POST requests send data to a server, which is useful for form submissions or API calls. Headers provide metadata about the request and help identify your client.
For web scraping, we primarily use GET requests. However, headers are crucial because they can mean the difference between a successful scrape and getting blocked.
Setting Headers to Avoid Detection
Modern websites analyze request headers to detect bots. By mimicking a real browser, we can significantly reduce the chance of being blocked. Here is how to do that using cURL:
<?php
$ch = curl_init();
$url = "https://news.ycombinator.com/";
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language: en-US,en;q=0.5',
'Accept-Encoding: gzip, deflate, br',
'Connection: keep-alive'
]);
$response = curl_exec($ch);
curl_close($ch);
echo $response;
?>
Upgrading to Guzzle for Better Performance
While cURL works fine, Guzzle is a more modern HTTP client that offers several advantages. It has a cleaner, object-oriented API with built-in exception handling. Guzzle provides native support for asynchronous requests and gives you better error messages for debugging. Most importantly, Guzzle makes it easy to send multiple requests concurrently, which dramatically improves scraper performance.
The Power of Asynchronous Requests
When scraping multiple pages, synchronous requests become a bottleneck. Each request must wait for the previous one to complete before starting. With asynchronous requests, multiple requests can be sent simultaneously and we can wait for all of them to complete.
The performance difference is dramatic:
- 10 synchronous requests: ~5 seconds
- 10 asynchronous requests: ~0.5 seconds (10x faster!)
- 100 requests: 50 seconds vs 5 seconds
- 1,000 requests: 8+ minutes vs less than 1 minute
The following examples compare synchronous and asynchronous approaches:
Synchronous requests (slow):
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$client = new Client();
$start = microtime(true);
for ($i = 1; $i <= 10; $i++) {
$response = $client->request('GET', "https://news.ycombinator.com/news?p={$i}");
echo "Page {$i} fetched\n";
}
$end = microtime(true);
echo "Time taken: " . ($end - $start) . " seconds\n";
// Output: Time taken: ~5 seconds
?>
Asynchronous requests (fast):
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Promise;
$client = new Client();
$start = microtime(true);
$promises = [];
for ($i = 1; $i <= 10; $i++) {
$promises[] = $client->getAsync("https://news.ycombinator.com/news?p={$i}");
}
$results = Promise\Utils::settle($promises)->wait();
$end = microtime(true);
echo "Time taken: " . ($end - $start) . " seconds\n";
// Output: Time taken: ~0.5 seconds (10x faster!)
?>
Parsing HTML Content
After efficiently retrieving web pages, the next step is to extract data from them. HTML documents have a tree-like Document Object Model (DOM) structure that can be navigated and queried.
Symfony's DomCrawler is an excellent library for parsing HTML. It supports CSS selectors with familiar syntax like .class and #id. You can also use XPath expressions for more powerful queries when dealing with complex selections. DomCrawler also provides methods to navigate through parent, child, and sibling elements in the DOM tree.
Extracting Data with XPath
XPath is particularly powerful for web scraping. In this example, I will extract story data from Hacker News including titles, URLs, points, and comment counts:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
$client = new Client();
$response = $client->request('GET', 'https://news.ycombinator.com/');
$html = (string) $response->getBody();
$crawler = new Crawler($html);
$stories = [];
$crawler->filterXPath('//tr[@class="athing"]')->each(function (Crawler $node) use (&$stories) {
$titleNode = $node->filterXPath('.//span[@class="titleline"]/a')->first();
$story = [
'title' => $titleNode->text(),
'url' => $titleNode->attr('href'),
'id' => $node->attr('id')
];
$stories[] = $story;
});
$crawler->filterXPath('//tr[@class="athing"]/following-sibling::tr[1]')->each(function (Crawler $node, $i) use (&$stories) {
$scoreNode = $node->filterXPath('.//span[@class="score"]');
$commentsNode = $node->filterXPath('.//a[contains(text(), "comment")]');
if ($scoreNode->count() > 0) {
$stories[$i]['points'] = $scoreNode->text();
}
if ($commentsNode->count() > 0) {
$stories[$i]['comments'] = $commentsNode->text();
}
});
print_r($stories);
?>
Complete Hacker News Scraper
The following section puts everything together into a complete, production-ready scraper. This example combines async requests, HTML parsing, and proper error handling.
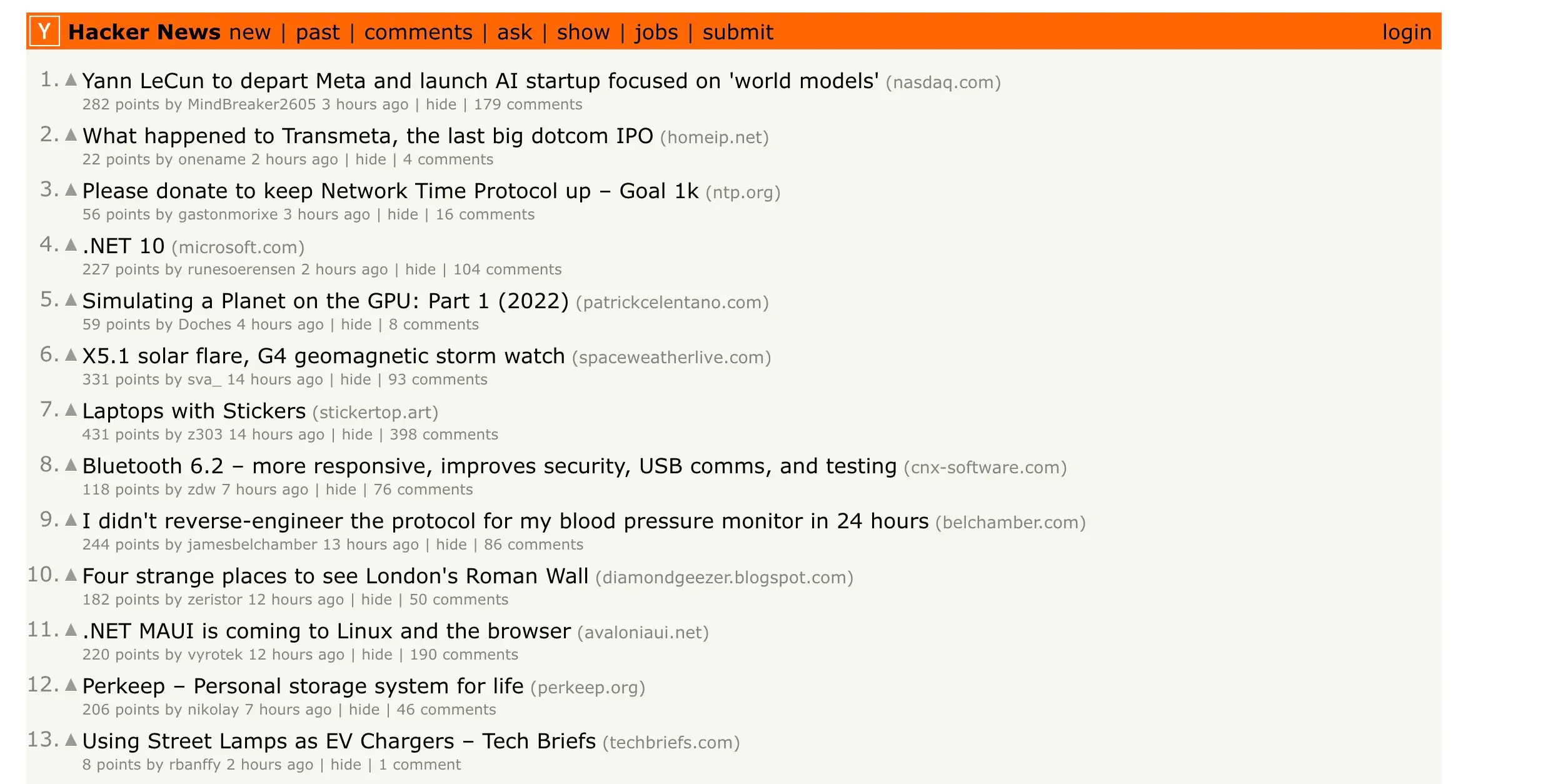 The full project code is available on GitHub.
The full project code is available on GitHub.
How It Works
Our scraper follows a clear workflow. First, we establish a global HTTP client with browser-like headers. Then we create async requests for multiple pages and define parsing logic to extract story data. We handle errors gracefully using try-catch blocks and finally return structured JSON data for easy consumption.
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
use GuzzleHttp\Promise;
use Symfony\Component\DomCrawler\Crawler;
$client = new Client([
'headers' => [
'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
]
]);
function scrapeHackerNews($client, $numPages = 5) {
$promises = [];
for ($i = 1; $i <= $numPages; $i++) {
$promises[] = $client->getAsync("https://news.ycombinator.com/news?p={$i}");
}
return $promises;
}
function parseStories($html) {
$crawler = new Crawler($html);
$stories = [];
$crawler->filterXPath('//tr[@class="athing"]')->each(function (Crawler $node) use (&$stories) {
$titleNode = $node->filterXPath('.//span[@class="titleline"]/a')->first();
$story = [
'title' => $titleNode->text(),
'url' => $titleNode->attr('href')
];
$stories[] = $story;
});
return $stories;
}
$promises = scrapeHackerNews($client, 3);
$allStories = [];
try {
$results = Promise\Utils::settle($promises)->wait();
foreach ($results as $result) {
if ($result['state'] === 'fulfilled') {
$html = (string) $result['value']->getBody();
$stories = parseStories($html);
$allStories = array_merge($allStories, $stories);
} else {
error_log("Request failed: " . $result['reason']);
}
}
} catch (Exception $e) {
error_log("Error: " . $e->getMessage());
}
header('Content-Type: application/json');
echo json_encode($allStories, JSON_PRETTY_PRINT);
?>
Handling Anti-Bot Protection
The scraper we built works great for simple websites like Hacker News. However, many modern websites employ sophisticated anti-bot protection. They use IP-based blocking to rate limit and ban suspicious addresses. You might encounter CAPTCHA challenges that require human verification. Some sites use JavaScript challenges from services like Cloudflare or DataDome. Advanced systems even analyze browser behavior through fingerprinting to detect bots.
Building and maintaining infrastructure to bypass these protections is complex, expensive, and time-consuming. This is where ScrapingForge comes in.
Using ScrapingForge API
ScrapingForge is a professional web scraping API that handles all anti-bot challenges automatically. When you route your requests through ScrapingForge, it rotates through thousands of premium proxies so you never get IP banned. It automatically solves CAPTCHAs for you and renders JavaScript using headless browsers for dynamic websites. ScrapingForge properly handles cookies and sessions, maintaining a 99%+ success rate on most websites.
Here is how to integrate ScrapingForge into your PHP scraper:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
$client = new Client([
'base_uri' => 'https://api.scrapingforge.com/v1/scraper',
'headers' => [
'X-API-Key' => 'YOUR_API_KEY_HERE'
]
]);
$response = $client->request('POST', 'scrape', [
'json' => [
'url' => 'https://www.amazon.com/s?k=laptop',
'render_js' => true,
'premium_proxy' => true
]
]);
$html = (string) $response->getBody();
$crawler = new \Symfony\Component\DomCrawler\Crawler($html);
$products = [];
$crawler->filter('.s-result-item')->each(function ($node) use (&$products) {
$title = $node->filter('h2 a span')->text('');
$price = $node->filter('.a-price-whole')->text('');
if ($title && $price) {
$products[] = [
'title' => $title,
'price' => $price
];
}
});
echo json_encode($products, JSON_PRETTY_PRINT);
?>
Key Benefits of ScrapingForge
ScrapingForge gives you access to thousands of premium residential and datacenter proxies with automatic rotation. It automatically bypasses reCAPTCHA, hCaptcha, and other verification challenges. The service provides full browser automation for JavaScript-heavy dynamic websites. You get a 99%+ success rate on most websites, including tough targets like Amazon, Google, and LinkedIn. The pricing is cost-effective because you only pay for successful requests with no infrastructure maintenance costs. The platform is highly scalable and can handle millions of requests without you having to manage servers or proxies.
Best Practices for PHP Web Scraping
Before wrapping up, I want to share some important best practices that will help you scrape responsibly and effectively.
1. Respect robots.txt
Always check a website's robots.txt file to see which paths are allowed for scraping. You can find this file at https://example.com/robots.txt. It tells you which parts of the site the owners want to keep private from bots.
2. Implement Rate Limiting
Do not overwhelm target servers with too many requests at once. Add delays between your requests to be respectful of the server resources:
// Add delay between requests
sleep(1); // Wait 1 second
usleep(500000); // Wait 0.5 seconds
3. Handle Errors Gracefully
Always use try-catch blocks and log errors so you know when something goes wrong:
try {
$response = $client->request('GET', $url);
} catch (\Exception $e) {
error_log("Scraping error: " . $e->getMessage());
}
4. Use User-Agent Rotation
Rotate between different user agents to make your requests appear more natural. This helps you blend in with regular browser traffic:
$userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)...',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)...',
'Mozilla/5.0 (X11; Linux x86_64)...'
];
$randomUA = $userAgents[array_rand($userAgents)];
Conclusion
In this tutorial, I have covered the complete journey of web scraping with PHP. We started with making basic HTTP requests using cURL and Guzzle, then learned how to set proper headers to avoid detection. I showed you how to parse HTML using DomCrawler with XPath and CSS selectors. We implemented async requests to get 10x performance improvement and built a complete scraper with proper error handling. Finally, we looked at how to bypass anti-bot protection using ScrapingForge API.
While PHP may not be the first choice for web scraping, it is a capable option—especially if you are already working in a PHP environment. The combination of Guzzle and DomCrawler provides a powerful, maintainable scraping solution.
For production scraping that requires reliability and scale, consider using ScrapingForge to handle the complex infrastructure and anti-bot challenges automatically.
Happy scraping! 🚀
Web Scraping Steam Store with JavaScript and Node.js
Learn web scraping with JavaScript and Node.js. Step-by-step tutorial to scrape Steam Store for game titles, prices, and discounts using modern Node.js.
What Is a Web Scraping API & Why Not Build One
Discover why web scraping APIs are the future of data extraction. Learn about the hidden challenges of DIY scraping and when it makes sense to build vs. buy.